Master Few-Shot Learning with Prompt-Poet and Langchain
With the advent of large language models (LLMs) such as Llama 70B, few-shot learning offers a powerful way to achieve high performance even with limited labeled data. In this post, we'll explore how to leverage few-shot learning with LLMs for effective text classification.

In this post, I will demonstrate how to do few shot learning using a LLM for doing a text classification task. I will also introduce a Python library called Prompt-Poet for maintaining prompts that uses a mixture of YAML and Jinja templating.
Traditional Models
Text Classification is a crucial task in NLP, it has various applications across domains. Some examples:
- Spam vs Non-Spam
- Topic Classification
- Fake News Identification
- Medical Records to Disease Classification
- Customer Support to route enquiries to specific teams
Compared to a traditional models, using generative AI to train such models has some pros and cons.
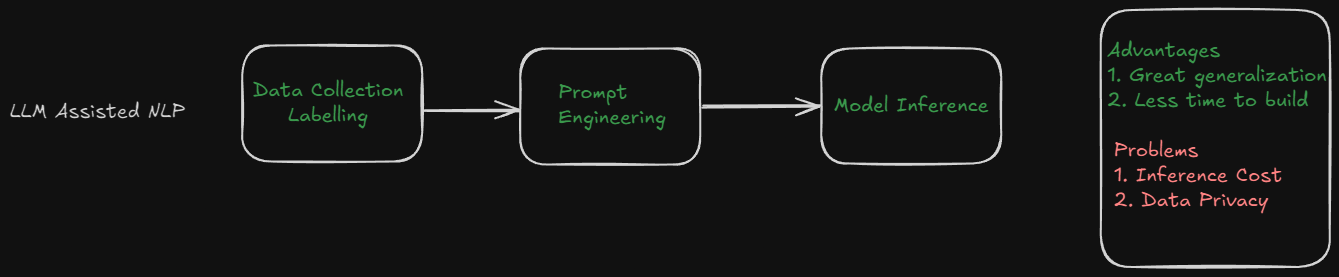
- Data Efficiency: They require little to no data. You can use zero-shot prompting to classify your text.
- Training Data Generation: You can use a LLM to gather noisy labels and use the generated labels to train another model.
- Performance: The performance might vary a lot. It depends on how complicated your task is and your prompt engineering!
- Inference Cost: The inference is expensive. Since the models are quite large to be hosted by yourself, you have to rely on external API providers. This may lead to security and privacy concerns.
Traditional methods for doing text classification involve creation of training data, feature engineering methods like TfIdf or Word Vectors, model building and validation.
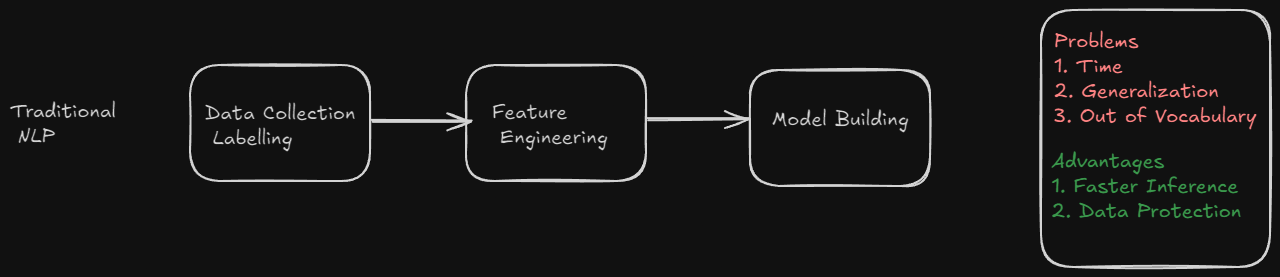
- They require a lot of training data.
- They discard sequential information in text by considering sentences as bag of words.
- In spite of these disadvantages, they are simple to train, offer fast inference, establish strong baselines. The data is secure and private as the model can be run from anywhere.
Using Prompt-Poet for Zero Shot Learning
Let us build a zero-shot learning model for text classification. I will be using Groq to access Llama 70B model from Meta and Langchain library to communicate with the model.
pip install langchain_core, langchain_groq, prompt_poet, tqdm, pandas, datasetsInstalling Packages
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
from typing import List, Literal, Annotated
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.tools import tool
import getpass
from typing import List, Optional
import numpy as np
from datasets import load_dataset
from prompt_poet import Prompt
from tqdm import tqdm
import pandas as pd
from unicodedata import normalize
def norm_text(input_text):
return normalize('NFKD', input_text).encode('ascii','ignore').decode('ascii')
llama_70b_llm = ChatGroq(api_key=YOUR_API_KEY_HERE, temperature=0, model_name="llama3-groq-70b-8192-tool-use-preview")Imports
To define a prompt in Prompt-Poet, you have to use the following structure.
raw_template = """
- name: system instructions
role: system
content: |
You are an expert in classifying a given text into {{ text_classfication_classes }}
- name: user query
role: user
content: |
Please extract label of the following text.
{{ norm_text(text) }}
"""Defining zero-shot prompt
name: system instructionsThis block defines the name.role: systemThis block defines that this block should be treated as system.contentThis block defines the message{{text_classfication_classes}}This defines the input that we can pass as a parameter.
norm_text is the function here.To create the template, we need to create a dictionary with the data it needs. We can now pass the template data to the Prompt function to create the prompt.
template_data = {"text_classfication_classes": "Spam or Ham", "text": "Win $1000000 NOW!!!","norm_text":norm_text}
prompt = Prompt(
raw_template=raw_template,
template_data=template_data
)Now, if we look at prompt.messages, we get this as ouput.
[{'role': 'system',
'content': 'You are an expert in classifying a given text into Spam or Ham'},
{'role': 'user',
'content': 'Please extract label of the following text.\nWin $1000000 NOW!!!'}]To execute the prompt, we call invoke the LLM using the prompt.
response = llama_70b_llm.invoke(prompt.messages)
print(response.content)
Invoking LLM
The label for the given text is "Spam".
Response
Adding Structured Outputs
LLM Prompting will usually print a natural language output. We can structure the response from LLM into a JSON using a predefined Pydantic object.
Let us create a structure for the output.
class Classification(BaseModel):
"""Function that Classifies the text into Spam or Ham"""
classification_label: str= Field(default=None,enum=["Spam","Ham","spam","ham"])
explanation: str = Field(default=None,description="Explain why you gave that label to this text. Keep your answers short and precise. I will tip you $20 for a good explanation. ")classification_labelIt can only take Spam or Ham as classes- The description is important here, Langchain uses this information and passes it to the LLM
We can now create a structured output by modifying the original LLM with Classification class.
llama_70b_llm_cls_head = llama_70b_llm.with_structured_output(Classification)Now, if we invoke the LLM, we always get a structured output.
result = llama_70b_llm_cls_head.invoke(prompt.messages)
print(result)
Invoking LLM
Classification(classification_label='Spam', explanation='The text contains an exaggerated claim of winning a large sum of money, which is a common tactic used in spam messages.')Result
By using structured outputs, we can ensure that the LLM always responds in the format that we want.
Few Shot Learning
In few-shot learning, we provide the LLM with few examples of each class. This ensures that the LLM understands the task we are trying to do and improves it's performance.
We will use data from ucirvine/sms_spam and validate this approach. Let's load the dataset and create a function to select some examples from each class.
ds = load_dataset("ucirvine/sms_spam")['train'].train_test_split(test_size=0.01,stratify_by_column="label")
def generate_samples(dataset, num_samples_per_class=5, label_column=None, text_column=None):
if label_column is None or text_column is None:
raise ValueError("Both label_column and text_column must be provided.")
# Get unique labels and shuffle the dataset
unique_labels = dataset.unique(label_column)
dataset = dataset.shuffle(seed=42)
label_names = dataset.features[label_column].names
# Initialize a dictionary to store samples per class name
samples_per_class = {label_name: [] for label_name in label_names}
# Collect samples for each class
for example in dataset:
label = example[label_column]
label_name = label_names[label]
if len(samples_per_class[label_name]) < num_samples_per_class:
samples_per_class[label_name].append(example)
# Create a list of {label, text} pairs
label_text_pairs = []
for label_name, samples in samples_per_class.items():
for sample in samples:
label_text_pairs.append({"label": label_name, "text": sample[text_column]})
# Yield (text, label) pairs
for each_sample in label_text_pairs:
yield (norm_text(each_sample['text'].strip()), each_sample['label'].strip())
samples = generate_samples(ds['train'],text_column='sms',label_column='label')
samples = list(samples)Function to select random samples from training data from each class
Now, let's create a template for few-shot learning. Prompt-poet enables us to write complicated control flows within the YAML and simplifies the whole process.
few_shot_template = """
- name: system instructions
role: system
content: |
You are an expert in classifying a given text into {{ text_classfication_classes }}.
These are some of the examples that you can use to do this task.
{% for each_example, each_label in samples %}
Text: {{ each_example }} Label: {{ each_label}}
{% endfor %}
- name: user query
role: user
content: |
Extract the properties listed in Classification function : {{ escape_special_characters(text) }}
"""Template for Few-shot learning
{% for each_example, each_label in samples %}allows us to loop over each sampleText: {{ each_example }} Label: {{ each_label}}allows us to format our text-label pairs{% endfor %}ends the for loop
Now, let's create the prompt using the template.
template_data = {"text_classfication_classes": "Spam or Ham",
"text": "No Deposit Required. Play for FREE and Win for Real!..-ettzhr.",
"samples":samples}
few_shot_prompt = Prompt(
raw_template=few_shot_template,
template_data=template_data
)
Creating Prompt
If you look at the prompt that it created, it will have all the samples.
You are an expert in classifying a given text into Spam or Ham.
These are some of the examples that you can use to do this task.
Text: Been running but only managed 5 minutes and then needed oxygen! Might have to resort to the roller option! Label: ham
Text: Omg how did u know what I ate? Label: ham
Text: Hi here. have birth at on the to at 8lb 7oz. Mother and baby doing brilliantly. Label: ham
Text: Haha yeah, 2 oz is kind of a shitload Label: ham
Text: Aah! A cuddle would be lush! I'd need lots of tea and soup before any kind of fumbling! Label: ham
Text: Free video camera phones with Half Price line rental for 12 mths and 500 cross ntwk mins 100 txts. Call MobileUpd8 08001950382 or Call2OptOut/674 Label: spam
Text: U have a secret admirer who is looking 2 make contact with U-find out who they R*reveal who thinks UR so special-call on 09058094599 Label: spam
Text: If you don't, your prize will go to another customer. T&C at www.t-c.biz 18+ 150p/min Polo Ltd Suite 373 London W1J 6HL Please call back if busy Label: spam
Text: As one of our registered subscribers u can enter the draw 4 a 100 G.B. gift voucher by replying with ENTER. To unsubscribe text STOP Label: spam
Text: **FREE MESSAGE**Thanks for using the Auction Subscription Service. 18 . 150p/MSGRCVD 2 Skip an Auction txt OUT. 2 Unsubscribe txt STOP CustomerCare 08718726270 Label: spamCreated Few-Shot Prompt
Now, we can invoke the LLM with structured output to get the label for text
result = llama_70b_llm_cls_head.invoke(few_shot_prompt.messages)
Classification(classification_label='spam', explanation='The text contains promotional language and a call to action, which is typical of spam messages.')Result
Perfect, we now have a few shot model that classifies text into Spam or Ham that uses structured outputs.
This approach may not work all the time. For your specific task, it might need you to do multiple iterations on improving the prompt and validating the results on a test set.
Always remember that LLMs can hallucinate and return confident answers even when uncertain. It is important to verify the results manually before deploying any model.